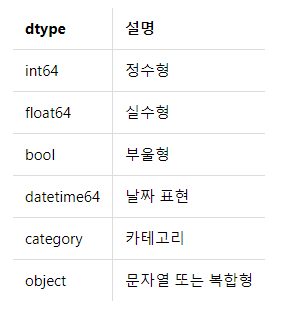
값 대치 값 대치 (딕셔너리) s = pd.Series([1, 2, 3]) # 3행 1열의 샘플 데이터 mapping = { 1:"drop", 2:"the", 3:"table" } # 딕셔너리 구조의 맵핑할 데이터 s1 = s.map(mapping) # 딕셔너리를 인자로 map 호출 print(s1) # 결과 0 drop 1 the 2 table dtype: object 값 대치 (함수) s.map(lambda x: x**2) # 각각 제곱 # 결과 0 1 1 4 2 9 dtype: int64 값 변환(함수 호출) # 제곱 함수 선언 def squared(value): return value * value # apply s.apply(squared) # 결과 0 1 1 4 2 9 dtype: int64 ..