반응형
데이터 전처리 과정
1. 문제 정의 및 가설
문제를 명확하게 정의하는 것이 가장 중요하다. 문제 정의부터 잘못 접근했다면 나오는 결과 또한 무의미한 결과이기 때문이다.
문제 정의에 앞서 배경을 살펴보고 전체적인 맥락을 이해하는데 중점을 둔다. 배경을 이해하는데 도움이되는 것은 도메인 지식이다.
문제를 정의했다면 “이 문제를 해결함으로 어떤 것이 해결 되는가?” 를 생각해야 한다. 즉 데이터 분석의 목적을 정의하고 그 문제를 해결하기 위한 가설을 세워야한다.
i. 프로젝트시 고려사항
- 목적과 데이터 특성에 맞는 모델을 무엇인가?
- 일반화 가능성은 어떠한가?
- 성능 측정의 지표는? 성능을 높이기 위해 어떻게 Feature Engineering을 진행할 것인가?
- 제품 혹은 시스템에 모델을 적용할 시 계산량이나 언어 특성에 관해 고려할 부분이 있는가?
- 모델/파라미터 업데이트 주기 및 방식은 어떻게 협의 할 것인가?
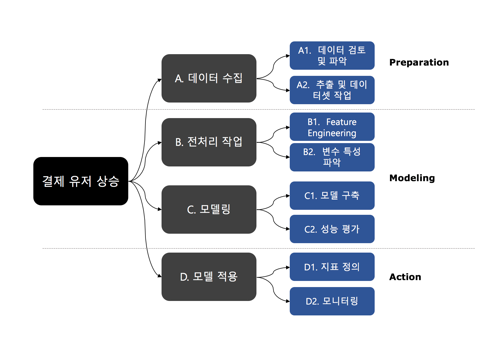
ii. Logic Tree 작성
간단한 다이어그램을 그려 로직 트리를 작성해본다. 프로젝트의 흐름을 고려해서 구성한다.
2. 데이터 전처리
전체 프로젝트에서 문제 정의가 가장 중요하듯 데이터를 모델에 넣기 전에 데이터 전처리가 가장 중요하다. 데이터 전처리가 잘못되면 모델 성능이 아무리 좋아도 좋은 결과를 기대하기 힘들기 때문이다.
데이터 전처리 과정에서 가장 먼저 해야할 일은 데이터를 불러오고 첫 행 일부분과 마지막 행 일부분을 토대로 분석하는 것이다.
i. 데이터 불러오기 및 인덱스 지정
# 데이터프레임 읽고 초반, 후반 행 확인하기
df = pd.read_csv("testset.csv", index_col=0)
df.head()
df.tail()
# 인덱스 지정
df.set_index("iduser", inplace=True)
# 컬럼별 type 확인 및 결측치 확인
df.info()
df.isnull().sum()
ii. 결측치 처리
- Null 값이 포함되어 있는 사례가 있는지
- 값은 있지만 전혀 다른 값이나 범위를 벗어나는 이상치가 있는지
- 샘플 수는 충분한지
3. 모델 생성
모델링 단계에 들어섰더라도 데이터 전처리 과정에 끝난 것은 아니다. 일반적으로 모델의 성능은 해당 알고리즘의 차이보다 전처리를 어떻게 했는지에 따라 더 많이 영향을 받는 것으로 알려져 있다.
따라서 측정했을 때 모델의 성능이 만족스럽지 않다면 여러 알고리즘을 사용하는것과 더불어 전처리 단계를 다시 진행해야 할 수도 있다.
i. 모델 구축 전 확인사항
- 범주형, 연속형 데이터 형식의 적절성
- 이상치 및 결측치 처리 여부
- 스케일링 및 분포 변환
- 다중공선성 문제
- 예측변수(y)의 분포 imbalance 문제
- 변수 축소 및 파생 변수 생성
🔗참조 링크
반응형
'BigData' 카테고리의 다른 글
| PointCloud란(pcd, ply) (0) | 2022.05.16 |
|---|